|
|
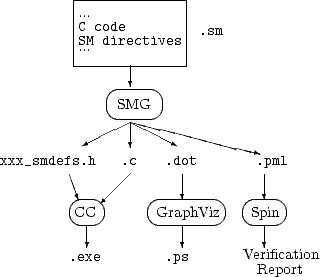
AbstractThe SMG utility can be used to scan an input file for specific directives that describe a State Machine (States, Events, Transitions, and associated Code segments) and generate several different outputs: C code to implement that State Machine, Promela code to implement a formal verification of the State Machine using Spin, and a graphical representation of that State Machine for analytical purposes. In mechanical terms, the SMG may be thought of as a specific-purpose C preprocessor. The SMG utility may be obtained from: http://smg.sf.net/ |
Modern programming techniques are often oriented around a procedural language such as C or a similarly structured object-oriented implementation. When developing software using these languages, the prevalent coding methodology is to design a set of instructions and functions that will perform the intended sequence of tasks, using a top-down approach. This sequence of tasks is identified as the primary objective of the program being developed. This programming methodology is referred to as task-oriented programming.
Frequently, however, the attention to developing support for portions of the code not related to the primary objective is diminished or in some cases non-existent. This results in unhandled or badly handled error paths and an inflexibility of the code regarding changes or deviations in input or operating environment. The top-down approach can exacerbate this issue as the focus narrows as details are introduced, thereby causing those details to be developed with primarily local concerns.
Additionally complicating this programming methodology is the attempt to introduce multi-threaded scheduling to improve the overall responsiveness of the program to multiple simultaneous inputs. When introducing threading significant attention must be provided to properly protecting common data structures and maintaining each thread relative to all other threads and the overall program state.
Finally, validation of the resulting code is left to a rote process of verifying functionality and output of the codewhen presented with sample sets of input; coverage tools attempt to verify that most of the written code has been executed, but this does not necessarily mean that the full range of input or sequencing has been tested in the process. A technique known as modelling and formal verification can be used to abstract the functionality of the code, but this is usually only used in the architectural and early design phases; the resemblance of the final code to the formal verification model is tenuous at best and often minimal. Developers tend to handle unexpected input or events as “bugs” by providing local fixes to ensure that their code does not fail when these occur, but without consideration of how the system as a whole should properly handle those situations and rarely by returning to and updating the formal verification model.
Another one of the frequent challenges in developing computer software is implementing and maintaining code that can fully manage an operation that is subject to asynchronous events. Asynchronous events can take many forms, including: user-input, operation completion notifications, interrupts, and operation requests. In general, an asynchronous event can occur at any time and the software must be capable of determining what the appropriate response to that event is at that point in time.
These event-oriented environments are found in most non-computation oriented code and are especially prevalent in: Internet Servers, Device Drivers, and GUI implementations.
The task-oriented coding style discussed previously makes it difficult to anticipate and handle exceptions to the sequence of tasks which are introduced by Asynchronous Events and also leads to assumptions regarding when events will occur and what types of events will occur at various delivery points. Often ignored or lightly-addressed is the importance of determining the appropriate response to all types of events that may occur at each point where they may occur.
One technique commonly used in applications written for an Asynchronous Event environment is to declare an event queue onto which all events are placed in order of occurrence. The code then removes an event from the head of the queue, processes that event in a task-oriented manner until the event has been completely handled, and then returns to the queue to obtain the next event. This algorithm may be useful in some circumstances but its appropriateness is often invalid when events cannot be queued, when events must be prioritized, and when some events may interrupt other events.
An alternative coding style used in these situations is the Event-Driven State Machine or EDSM methodology1. In this methodology, events are typically delivered to a common entry point and then a specific function or switch statement is invoked based on the current state or the event. Once in that code has been invoked, the other parameter (entry or state) is examined to select the code to execute for that state/event combination. While this style is more flexible in terms of handling unexpected events it is more arduous to develop code in this style due to the mechanics of reproducing state and event selection code throughout the code and the loss of the “flow” perspective for the primary sequence of tasks.
Some software designs do implement an EDSM methodology, but unfortunately, most of the software in these implementations focuses on the expected sequence of operations only; it’s frequently the case that not all events are handled at each event-delivery juncture in the code.
Furthermore, in situations where state machines are implemented in the software, the completeness of the state machine tends to logarithmically increase the complexity and obscurity of that state machine, making them hard to understand and maintain. Each possible state has to consider the potential occurrence of an ever-increasing number of events, and the addition of each state causes an event-number of new paths through the state machine.
This type of code is difficult to maintain, especially for developers introduced to the code after it is written. State machine code is often spread throughout the body of the main code, making it hard to understand the entirety of the state machine. Furthermore, the state machine code has significant side effects; any change to a state machine’s structure (i.e. adding a new state or changing the response to an event) will significantly impact code executing to handle future events. Understanding, predicting, and assessing the validity of any changes to the state machine quickly becomes a monumental task as the size of the state machine grows.
A formal verification model is a highly useful tool to properly evaluate and manage additions (states or events) to this type of code, but again, since the formal verification model is often retired or divergent at this point in development the opportunity is not often available. Some institutions even separate the coding and formal verification modelling into separate groups, the former being handled by architects and the latter by developers. Sometimes the developers are not even aware of the existence of formal verification models.
Another more recent advancement facing many implementations is the introduction of non-blocking function calls for performing various asynchronous tasks such as: I/O operations and remote procedure calls (RPC) found in distributed environments. In these situations, the program’s initial request is not completed when the request call completes; instead the request is processed in parallel or at some later point in time and when completed, the initial program is notified of that completion (usually by invocation of a callback function).
This complicates the normally task-oriented methodology in the following ways:
These complications require significant additional care in properly and efficiently implementing applications for this type of environment.
The proposed approach to handling these issues is to attempt to reconcile the EDSM methodology with the more customary task-oriented programming styles. In order to do this, we seek to automate the mechanics of EDSM and re-introduce the conceptual perspective of task-oriented coding styles. This is done by beginning with the EDSM methodology and making the following set of observations and changes.
To facilitate this approach, the SMG tool has been developed. Using the SMG tool, the developer describes the state machine by a set of SMG directives interspersed with the program’s normal C code.
The SMG directives are intended to be more succinct in describing the state machine than the correspondingC code, thereby allowing the state machine to be more easily recognized and understood even at the input specification level. The SMG directives also allow default functionality to be specified and allows the state machine to be more “naturally” described in parallel to the task-oriented code segments.
Once the code (including SMG directives) has been developed, the code is passed through the State Machine Generator (SMG) as a preprocessing stage. The SMG utility converts the SMG directives into C code which implements the described state machine, allowing the result to be passed to the C compiler as a combination of the state machine and the task-oriented code, providing a complete functional solution.
The SMG utility also produces a description of the state machine that may be passed to the GraphViz utility to obtain a graphical representation of the state machine. The graphical representation allows easy interpretation and maintenance of the state machine.
The graphical representation shows the various states as nodes on the graphs and labels the arcs that connect those nodes with the names of the events that cause that transition. The arc labels also indicate which code objects are executed before and after the event causes the actual state to change.
Expected transitions are represented by thick arcs, making it easy to follow the normal code flow and differentiated from unusual or error handling transitions.
SMG will also automatically generate an error state if there are any states wherein the result of an event is not defined explicitly by SMG directives. The corresponding C code generated will cause a runtime error call to a programmer-supplied error routine if this undefined event transition occurs). All transitions to this error state will be labelled as errors for easy analysis; final versions of the code should not contain any undefined transitions of this type.
SMG will also group states in order to simplify the diagram. For example, if a group of 5 states have normal transitions to other states, but they all transition to an error state when a particular event occurs, SMG will assign those 5 states to a group and separately indicate that the group transitions to the error state on that event. This grouping is performed automatically.
The third SMG output is a SPIN/Promela model of the state machine. This model is automatically extracted from the states, events, and transitions defined by the SMG directives. It is therefore capable of describing the overall functionality of the system for SPIN functional verification without any additional input from the developer.
To supplement and refine the functional verification process, standard Promela code can be identified in the input file by bracketing SMG directives. The SMG utility will then direct this Promela code into the appropriate locations of the generated model as a parallel to the C code for the same transitions. In this way, both the overall functionality and detailed modelling code can be maintained in the SMG input file along with the corresponding C code. Thus, when additional states or events must be considered, or when one or more transitions must be redefined, the Promela model is correspondingly adjusted for continued formal verification.
As with the graphical and C outputs, the emitted Promela code generates assertions for undefined transitions, causing them to be flagged during formal verification (or they can be disabled to validate the currently defined subset of the application).
SMG development is done by designing C code modules as in a normal development operation and implementing SMG directives in one or more of the modules. Modules containing SMG directives typically have a “ .sm ” suffix to distinguish them from normal “ .c ” files (and so that SMG can generate a .c from the .sm ). The SMG directives can appear exlusively in a file themselves or then can be intermixed throughout the C code to the degree desired by the coding style being used.
The SMG directives also establish the States and Events that can occur, and optionally any entry points into the code that represent Events. The definitions of these States, Events, and entry points are output by SMG into a header include file ( xxx_smdefs.h ). All modules needing to use a State or Event value or make other references to the state machine can include this file to obtain the appropriate external definitions.
Once the C code and SMG directives have been written, the smg utility should be run on the .sm input files. The graphical state machine output should be examined to visually verify the implementation, followed by formal verification using SPIN and the output Promela model. Once the state machine has been formally verified, the output C code should be compiled by the C compiler and the linker for all C source files (some of which may have been output by the smg utility from .sm files). All errors during the development cycle are resolved in the input .sm file rather than making modifications to interim files; the resulting SMG model is therefore fully complete and functional.
|
|
In order to implement the EDSM methodology, SMG attempts to make minimal assumptions about the programming environment in which it will generate the state machine.
SMG will automatically provide C definitions for the states and events described in its directives. There are only two required C data types and based on the external interface for the program, and one required C function (the error handling function). The programmer can optionally define the syntax of event delivery points within the code with additional directives and C declarations, but this is not required. SMG does assume that if the event delivery points are not specified that the C program will provide the event-specific interface and invoke the state machine with an indication of the underlying event type.
The first required C data type must be a structure and is the SM_OBJ structure. This is assumed to be an instance of a structure that is global to the current task. This structure may contain anything that the programmer desires to implement but it must also contain the following field: <SM_NAME>_state_t sm_state; where <SM_NAME> is the declared name of the state machine.2 It is recommended that the SMG-related code not refer to any global writable data outside of the SM_OBJ structure although it is possible to deviate from this under certain circumstances.
The second required C data type is the SM_EVT type. This data type is assumed to represent any and all information related to the current event-initiated task. A common implementation is for the programmer to maintain a pool of SM_EVT structures which are used one-by-one as primary events arrive. The SM_EVT type may be any valid C data type; it is used to maintain the task-oriented context for the series of secondary events that are initiated by the primary event. The SMG code will not use the SM_EVT variable directly but will pass the value of this variable from the event-initiated state machine entry to the selected state/event handling code.3
SMG directives are designed for simplicity in both parsing and specification. Although the user can choose to design a preprocessing stage to preceed the SMG operation (e.g. m4), SMG directives are simply presented and designed to be unambiguously distinguishable from the C code into which they are placed.
The list of directives allows for significant flexibility in how the state machine is described and where the various operations occur. Some of these capabilities are only needed for special situations, and some are dependent on the way in which the state machine is implemented. Only the most basic directives are needed to identify a state machine and all other directives may be introduced only as needed when the basic directives are insufficient. The basic directives are listed below:
The reader is advised to attend to this subset of directives initially and to review the additional keywords presented in the SMG Guide once basic familiarity with SMG is attained.
This section describes all supported SMG keywords. As noted previously, the initial review should focus on the subset of common keywords, leaving the remaining keywords for more esoteric evaluation.
The syntax of SMG Directives is described in Figure 1. In the figure, <xxx> represents a user-supplied word, and <xxx>...represents one or more user-supplied words. Square braces (’[’ and ’]’) enclose optional portions of the directive and are not actually present in the directive. There are no restrictions on <xxx> words except those noted here and excepting whitespace. Some <xxx> words must be valid C identifiers: <state-machine-name> , <state-name>, and <event-name> .
All SMG directives are line oriented, must be contained on a single line, and must start with the SMG directive keyword at the first character on the line. The remainder of the line contains the arguments and values for the SMG directive as whitespace separated words, up to the end of the line; SMG directives do not support line-continuation.
|
This location is searched only if the optional second argument is specified on the SM_INCL line specifying the version of the interface. The N in the above path is replaced with the version number specified in the second argument and the * specifies a wildcard of all entries. Thus, if the optional version specified is “23”, the SM_INCL will search in all of the /usr/local/lib/*-v23 directories.
State machines which are not initialized at instantiation must be explicitly initialized with the <name>_State_Machine_Init operation before any events are delivered to that state machine.
Most uses of the EVENT keyword will specify only the <event_name>.
In situations where an event entry point is automatically defined (e.g. an Event Library), the optional <entry-code-tag> and <setup-code-tag> specify the code to be generated for the event handling entry point. The <setup-code-tag> should not be defined (i.e. not --) unless the <entry-code-tag> is also defined (in other words, if <entry-code-tag> is “--” then <setup-code-tag> must also be “--”).
The <new-state> may be “--” to indicate that there is no state change associated with this event in the current state.
The <pre-code-tag> and/or the <post-code-tag> elements may be “--” to indicate that there is no pre-state-change or post-state-change code to execute, respectively.
The <current-state> may be “*” to indicate that the transaction is a default transaction and applies to all states.
Another way of describing the difference between TRANS and TRANS+ is that a multiply defined state transition error will only be detected for TRANS directives.
The <new-state>, <pre-code-tag>, <post-code-tag>, and <current-state> fields may have the special values described in the TRANS directive and have the same effect.
The <new-state>, <pre-code-tag>, <post-code-tag>, and <current-state> fields may have the special values described in the TRANS directive and have the same effect.
Within the C code associated with the CODE tag, special keywords will be recognized and appropriate substitutions will be made in the output C code generated. All code-internal keywords are of the form “_/xxx” and may be one of the following:
If it is desireable to queue events to a state machine instead, for both external event deliveries and internally generated events, a separate mechanism must be provided by the user to implement this queueing. These directives should be used CAREFULLY.
Special code tags of HEADER and INIT may be used to specify Promela code that should be output to the header or the end (init) of the Promela file. One common initialization function is to declare the Promela channel used to deliver events to the state machine and then run the state machine, passing that channel. The channel messages should be declared as follows:
Where the first mtype should be either INITIALIZE_SM or SM_EVENT as appropriate, and the second mtype should be the initial state or the event name, respective to the first mtype. The depth of the channel should always be zero to accurately model the immediate delivery mechanism of the state machine; queued event delivery should use a separate queueing process rather than simply expanding the channel depth to provide the proper semantics.
See the output of the examples for more information.
When specifying the arguments for the SMG directives described above, there are special wildcards that are recognized by the SMG preprocessor that may be used in place of a more customary value for that argument:
Currently the SMG directives syntax is unchanged from the original publicly distributed version. In the future, the SMG directives syntax might need to change to accomodate additions, changes, and removals from the current syntax. To allow .sm files to be written to conform to multiple syntax forms and/or validate the needed syntax to interpret the current file, SMG automatically generates one or more context definitions describing the syntax interpretation used by that smg utility.
This automatically generated context definition may be checked with the SM_IF directive, even though no SM_DEFdirective explicitly defined that context.
Syntax extensions and additions are represented by additional automatically generated contexts defined simultaneously with the original syntax definition where the new syntax is backward-compatible with the original syntax. Syntactic changes incompatible with previous versions will be represented by a newly unique automatic context definition and the lack of previous definitions.
Also note that the syntax versioning supported in this manner is independent of the SMG utility version; multiple SMG utility versions might support identical syntax forms.
| Context | Description |
| SMG_SYNTAX_A | Original SMG syntax |
In addition to the SMG directives described above, there are a few requirements for successfully integrating the generated state machine C code into the rest of the software module:
The declaration for the error function to be provided by the user-supplied C code is defined as the <SM_NAME>_State_Machine_Error function in Figure 2.
User-supplied code may also call the error function, but if the err_id used matches the errors defined in Table 1 then the errtext and additional parameters must additionally match.
In the definition referenced, <SM_NAME> is replaced with the name of the state machine associated with this error (allowing separate error handlers for each state machine defined) and <SM_OBJ> and <SM_EVT> are replaced by the corresponding C type specifications from the similarly named SMG directives.
The errtext describes the error and may be followed by arguments to be used in printf-style format codes.
The err_id is an identifier value associated with this error. The errtext and the type and sequence of arguments for a specific err_id will never change, so error routines are free to key on the err_id value to perform specific actions as defined in Table 1.
|
|
In the definition referenced, <SM_NAME> is replaced with the name of the state machine to which the event is to be delivered. The sm_obj and sm_evt arguments must be the appropriate entities with types defined by the SM_OBJ and SM_EVT SMG directives, respectively. The event_code must be of type <SM_NAME>_event_t, where that type (and the actual event codes) are defined in the include header file output by the smg preprocessor.
This header file must be included into the .sm file at a minimum, and may be included into other .sm or .c/.h files in the module as needed. Its inclusion must be explicit by the developer to insure that the inclusion occurs at the right point in the code (e.g. following any other definitions needed by the SM definitions, but prior to actual usage of those definitions in the user-supplied code).
The SMG preprocessor is invoked from the command line prior to the C file compilation. It will produce a number of output files: a C code file ( .c ),a header include file ( .h ), a GraphViz dot input file ( .dot ), and a GraphViz output file in PostScript, GIF, MIF (Framemaker), or HTML imagemap format.
The SMG preprocessor may be invoked with no arguments or with the “ -h ” flag to obtain explicit usage information.
The following describes the command line arguments for SMG in more explicit detail than than provided by run-time help.
The SMG utility will automatically generate a set of support functions in addition to the primary <name>_State_Machine_Init and <name>_State_Machine_Eventfunctions. These supportfunctions may be used by the user’s event-specific code or other code to obtain user-readable names and descriptions of the States and Events defined in the .sm file.
The following support functions (defined in Figure 3) are generated automatically by SMG:
|
When the SMG utility is invoked with the -T argument, the generated SMG code contains run-time tracing output. By default, this tracing output causes information to be printed to stderr regarding the various events and state changes that occur when the SMG-generated state machine operates.
Some environments do not provide fprintf access to a stderr output stream, and other situations might desire custom control over the tracing output. These scenarios can be handled by overriding the default tracing code generated. The overrides are specified in the form of a set of #define statements in the .sm file. These #define statements should appear fairly early in the .sm file, and must appear before the inclusion of the xxx_smdefs.h file.
The following macros should be overridden with specific #define statements to modify the tracing behavior:
An interesting and useful extension of SMG usage is as a new method for defining interface libraries, especially for asynchronous event-driven interfaces. SMG features that make it very useful in working with event-driven architectures. Event-driven architectures are often asynchronous by nature and lend themselves to state machine management techniques, but SMG has the ability to specify entry points and setup code for those asynchronous entry points as an SMG Library that can be included into the applications SMG specification using the SM_INCL directive.
For example, consider a hypothetical windowing environment called ”Y”. Applications written for Y-windows must specify functions that are called when certain events occur within their window. The following events must be handled by a Y-windows application:
For a C development environment, there would be a Y-windows header file that defined these events and an event vector structure that would have to be initialized by the application:
typedef struct y_app_vtable {
void *y_mouse_b1(int x, int y);
// tricky: arguments switched:
void *y_mouse_b2(int y, int x);
void *y_key_entered(char keyval);
void *y_expose(void);
void *y_iconicize(void);
} y_app_vtable_t;
int y_app_mainloop(void);
|
The Y-windows application would then need to define functions to be entered into the y_app_vtable_t to handle the various events. The application would also need to call y_app_mainloop in its main routine after initializing so that Y-windows could begin processing events and passing them to the application’s handling functions.
The inconvenience of this methodology is that the process of creating the entry functions is a tedious, mechanical process that each Y-windows application must perform. This is exacerbated by the fact that the first thing that each entry point must do is check the global state to see how the event should be handled. For example, myapp.c would contain the following minimum code irrespective of the specifics of the application:
void myapp_mouse_b1(int x, int y) {
switch (app_state) {
case STATE_1:
<some code>
break;
case STATE_2:
<some code>
break;
:
}
}
void myapp_mouse_b2(int y, int x) {
switch (app_state) {
case STATE_1:
<some code>
break;
case STATE_2:
<some code>
break;
:
}
}
void myapp_key_entered(char keyval) {
// same as above...
}
void myapp_exposed(void) {
// same as above...
}
void myapp_iconicize(void) {
// same as above...
}
|
Instead of exposing the developer to the tedium of manually writing this template an SMG Library can be provided for Y-windows. This also removes the risk of entering it incorrectly, (eg. as void myapp_mouse_b1(int y, int x)which is syntactically but not functionally correct).
An SMG Library is nothing more than an SMG file that should be SM_INCL included into the main application and which defines the events and entry points for those events. This library can be developed once and re-used by all applications that operate within that event-driven architecture. The application developer is freed to focus on the actual functionality of the application in response to the events rather than the mechanics of program infrastructure.
A subset of the example above can be used to show how the introduction of an SMG Library changes the development. The initial introduction of the SMG Library generated state machine would replace all the switch statements in the example above into calls to the myapp_State_Machine_Eventfunction, thereby saving some of the superfluous repetition, but also making the entry points mere shells:
void myapp_iconicize(void) {
myapp_State_Machine_Event(&myapp_global,
<event_obj>,
Iconicize_E);
}
|
Because the state machine function will vector the code to the proper handling code, the entry point function needs to do little more than marshall the entry points arguments into the SM_EVT object and call the SMG’s state machine function.
In the revised example, it is assumed that myapp_global is a global structure whose type was reported to SMG by the SM_OBJ directive and that that structure contains the sm_state field, and it is also assumed that Iconicize_Eis the name of an event declared with the EVENTdirective (or implicitly as part of a TRANS directive).
The only yet-to-be determined portion of the revised code is the <event_obj> specification. This reference must be for a variable of a specific type that is useable to sufficiently represent the event in the state-machine-invoked code. For the myapp_iconicize entry point, there are no parameters and therefore the event is fully represented just by its presence. However, other events--such as the myapp_mouse_b1 --have associated parameters that will need to be available to the event handling code. Therefore, the following event representation structure is defined in myapp and declared with the SM_EVT directive:
typedef union {
struct {
int x;
int y;
} mouse_coords;
char keyval;
} myapp_y_event_t;
SM_EVT myapp_y_event_t *
|
Now all that’s needed is to pass a structure of that type to the SMG State Machine Event handler routine. There are a couple of choices as to where to obtain the structure:
The example shown in Figure 4 will use the simple memory allocation method. Also note that although all events must allocate the structure, different events mustinitialize the structure in a different manner and some events not at all, therefore a global macro can be used to perform the allocation.
|
The code in Figures 5, and 6 show how this is done by implementing the SMG Y-windows Library.
|
|
The code shown in these figures can be concatenated in order into a .sm source file and handled directly by SMG and a C compiler to generate the sample application.
|
|
|
|
Some types of entry points are passed a parameter which further defines the actual event which occurred. For example, instead of y_mouse_b1 and y_mouse_b2 , the Y-windows system could have just defined:
typedef enum { Mouse_B1, Mouse_B2 } MButton_t;
void *y_mouse(MButton_t button, int x, int y);
|
In cases like this, the event-specific handling must usually be different based on the actual event which occurred as indicated by the “sub-event” parameter. Rather than require the developer to perform this additional selection based on the sub-event, the SMG Library often provides a synthesized event for each of the sub-event types. In this example this means that the SMG Y-Windows Library would probably still provide y_mouse_b1and y_mouse_b2 events even though the actual event delivered to the application was simply a y_mouseevent.
Using an SMG LIbrary for code development means that the normal SMG development requirements apply plus those specific to the SMG Library. More specifically, the SMG Library must define for the user:
Please see the Examples directory of the SMG distribution for examples and discussions of the use of most of the state machine directives and options in fairly simple programs.
This example shows a simple example of a menu-driven file processing application that has an underspecified state machine.
The example is located in the Examples/file_ex1 subdirectory of the SMG distribution. The following sequence of events may be used to work with this example:
In the following example, the commands entered are shown in italics and the output of the utilities is shown in this font.
$ smg -viTP file_ex1
$ gcc -o file_ex1 file_ex1.c
|
Once built, it may be run by executing:
$ file_ex1 |
In addition to the executable, the source files ( file_ex1.c and file_ex1_smdefs.h ) may be examined. There is also a Promela model generated ( file_ex1.pml ) and a graphical representation of the state machine ( file_ex1S.ps )based on GraphViz directives ( file_ex1S.dot ).
Examining the graphical representation, it can easily be observed that the state machine is underspecified by the presence of the UNDEFINED_TRANSITION_RESULT state. This can be confirmed by performing a sequence of menu operations with the executable that lead to this error state and observing the output dynamically.
This example shows the use of an SMG-generated state machine for translating from Morse Code back to plain-text.
The example is located in the Examples/unmorse subdirectory of the SMG distribution. The following sequence of events may be used to work with this example:
In the following example, the commands entered are shown in italics and the output of the utilities is shown in this font.
$ smg -viTP unmorse
$ gcc -o unmorse unmorse.c
|
Once built, it may be run by executing:
$ unmorse '- . ... - -..-. .---- .-.-.-' Translation: TEST/1. $ |
In addition to the executable, the source files ( unmorse.c and unmorse_smdefs.h ) may be examined. There is also a Promela model generated ( unmorse.pml ) and a graphical representation of the state machine ( unmorseS.ps )based on GraphViz directives ( unmorseS.dot ).
SMG itself is written in Python code and therefore the system must have Python available. The initial version of Python used for SMG development was 1.5.2. Subsequent versions were maintained using Python 2.2; SMG should still run under Python 1.5.2 although this has not been specifically verified.
Python is available from: http://www.python.org/.
The GraphViz utility has been developed by AT&T Research and converts a text description of a graph into a representational Postscript figure. It can alternatively produce GIF, MIF or Web imap figures as well. The graphical output is very helpful in analyzing the resulting state machine.
SMG outputs a description of the state machine itself to a .dot file, which is then passed to GraphViz to generate the desired graphical output. The .dot file itself is not intended for analysis.
The GraphViz distribution version used for SMG development was 1.5. The GraphViz package is available at: http://www.research.att.com/sw/tools/graphviz
Promela and the Spin utility are independently developed by AT&T and are not related to the SMG preprocessor. Spin is available at: http://netlib.bell-labs.com/netlib/spin/whatispin.html
The SMG preprocessor is an independently developed utility and is not related to the GraphViz program developed by AT&T nor the Python language and interpreter developed by Guido van Rossum. Python is available from the above Web site. The GraphViz program is available independently from AT&T under their license.
Copyright (c) 2000-2001, Kevin Quick All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the conditions are met:
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS ”AS IS,” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDERS OR ANY CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.